如题。先介绍下概念。
Q1. 文件的哈希值是什么?
文件的哈希值是通过特定的哈希算法对文件内容进行计算后得到的固定长度的字符串(通常由数字和字母组成),它具有以下特点和相关信息:
- 哈希算法:常见的用于计算文件哈希值的算法包括 MD5、SHA-1、SHA-256、SHA-512 等。不同算法的计算方式和生成的哈希值长度不同。例如,MD5 算法生成的哈希值是 128 位(通常以 32 个十六进制字符表示),SHA-256 算法生成的哈希值是 256 位(以 64 个十六进制字符表示) 。
- 唯一性:理论上,不同内容的文件经过哈希算法计算后,应该得到不同的哈希值。这意味着如果两个文件的哈希值相同,那么它们的内容很可能是完全一样的(虽然存在极小概率的哈希碰撞,即不同内容产生相同哈希值,但这种情况非常罕见)。例如,在文件传输过程中,接收方可以计算接收到的文件的哈希值,并与发送方提供的原始文件哈希值进行比较,以验证文件在传输过程中是否完整无损,没有被篡改。
- 固定长度:无论文件的大小和内容如何,使用特定哈希算法计算得到的哈希值长度是固定的。例如,无论一个文本文件是几 KB 还是几 MB,使用 SHA-256 算法计算出的哈希值始终是 256 位。
- 不可逆性:哈希计算是一种单向操作,即可以通过文件内容计算出哈希值,但无法从哈希值反向推导出原始的文件内容。这使得哈希值在数据存储和安全验证等方面具有重要作用,比如在存储用户密码时,通常存储的是密码的哈希值,即使数据库被攻击,攻击者也难以从哈希值还原出原始密码。
哈希值在文件验证、数据完整性检查、文件去重、密码存储等众多领域都有广泛应用,是确保数据一致性和安全性的重要手段之一。
Q2. 比如一个文件 有1G大小,那么它的哈希值会多大?
文件哈希值的大小与文件本身的大小无关,而是由所使用的哈希算法决定。
常见的哈希算法及其生成的哈希值大小如下:
- MD5 算法:生成 128 位(16 字节)的哈希值,通常以 32 个十六进制字符表示。例如:
d41d8cd98f00b204e9800998ecf8427e,无论原文件是 1 字节还是 1GB 甚至更大,使用 MD5 算法计算出的哈希值固定是 128 位。 - SHA-1 算法:产生 160 位(20 字节)的哈希值,一般以 40 个十六进制字符呈现。比如:
da39a3ee5e6b4b0d3255bfef95601890afd80709,不管文件大小怎样变化,SHA-1 算法得到的哈希值长度不变。SHA-256 算法:输出 256 位(32 字节)的哈希值,以 64 个十六进制字符展示。例如:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855,即使是 1GB 的大文件,其 SHA-256 哈希值依然是 256 位。 - SHA-512 算法:生成 512 位(64 字节)的哈希值,用 128 个十六进制字符表示。如:
cf83e1357eefb8bdf1542850d66d8007d620e4050b5715dc83f4a921d36ce9ce47d0d13c5d85f2b0ff8318d2877eec2f63b931bd47417a81a538327af927da3e,同样不受文件大小影响。
所以,一个 1GB 大小的文件,其哈希值的大小取决于选择的哈希算法,而不是文件自身的体积大小。
需求:客户有200+份文件来源于不同的三方平台,但是客户不确定是否有重复文件。可能来源不同但是文件相同。客户希望筛出这些重复文件。供用户搜索用,这样用户就只会搜出唯一的文件结果,而不是来源于不同渠道的相同文件。
实现思路:
先获取所有文件的大小,并按照大小group by,这样相同大小的文件就会在一组。文件大小不同一定不属于相同文件,文件大小相同有可能属于相同文件,也有可能是不同的文件刚好大小相等。按照这方式,遍历所有相同大小的组。比对哈希值。文件大小不同的就不用比较了。肯定不是相同文件。
/*
代码说明
FindDuplicateFilesGrouped 方法:
首先遍历传入的文件路径数组,将每个文件的信息(Id、FileName、FileSize)封装到 FileInfoEntity 对象中,并添加到 fileInfos 列表。
接着按文件大小对 fileInfos 进行分组,得到 sizeGroups。
针对每个大小组,计算组内每个文件的哈希值,把具有相同哈希值的文件存到 hashGroups 字典里。
最后,将 hashGroups 中包含多个文件的组添加到 duplicateFileGroups 列表,该列表即为最终按组返回的重复文件结果。
通过这种方式,就能方便地找出所有重复文件,并将它们按组分类返回。
*/
FileComparisonTool.cs
//FileComparisonTool.cs
using System;
using System.Collections.Generic;
using System.Text;
using System.Threading.Tasks;
using System.IO;
using System.Linq;
using System.Security.Cryptography;
namespace ConsoleApp1_CompareFiles
{
// 文件实体类
public class FileInfoEntity
{
public Guid Id { get; set; }
public MemoryStream Stream { get; set; }
public string FileName { get; set; }
public long FileSize { get; set; }
}
// 文件比较工具类
public class FileComparisonTool
{
public static string[] GetAllFilesInFolder(string folderPath)
{
try
{
// 获取当前文件夹下的所有文件
string[] files = Directory.GetFiles(folderPath);
// 获取当前文件夹下的所有子文件夹
string[] subFolders = Directory.GetDirectories(folderPath);
foreach (string subFolder in subFolders)
{
// 递归调用获取子文件夹下的所有文件
string[] subFiles = GetAllFilesInFolder(subFolder);
files = files.Concat(subFiles).ToArray();
}
return files;
}
catch (Exception ex)
{
Console.WriteLine($"发生错误: {ex.Message}");
return new string[0];
}
}
// 计算文件哈希值
private static string CalculateHash(Stream stream)
{
using (SHA256 sha256 = SHA256.Create())
{
byte[] hashBytes = sha256.ComputeHash(stream);
return BitConverter.ToString(hashBytes).Replace("-", "").ToLowerInvariant();
}
}
// 入参是两个文件流,比较两个文件
public static bool CompareFiles(Stream stream1, Stream stream2)
{
stream1.Position = 0;
stream2.Position = 0;
string hash1 = CalculateHash(stream1);
string hash2 = CalculateHash(stream2);
return hash1 == hash2;
}
// 入参是两个文件路径,比较两个文件
public static bool CompareFiles(string filePath1, string filePath2)
{
using (FileStream stream1 = File.OpenRead(filePath1))
using (FileStream stream2 = File.OpenRead(filePath2))
{
return CompareFiles(stream1, stream2);
}
}
// 入参是文件路径的数组,找出重复文件
public static List<FileInfoEntity> FindDuplicateFiles(string[] filePaths)
{
var fileInfos = new List<FileInfoEntity>();
foreach (var filePath in filePaths)
{
var fileInfo = new FileInfo(filePath);
fileInfos.Add(new FileInfoEntity
{
Id = Guid.NewGuid(),
FileName = filePath,
FileSize = fileInfo.Length
});
}
var groups = fileInfos.GroupBy(f => f.FileSize);
var duplicateFiles = new List<FileInfoEntity>();
foreach (var group in groups)
{
if (group.Count() > 1)
{
var hashes = new Dictionary<string, FileInfoEntity>();
foreach (var file in group)
{
using (FileStream stream = File.OpenRead(file.FileName))
{
string hash = CalculateHash(stream);
if (hashes.ContainsKey(hash))
{
if (!duplicateFiles.Contains(hashes[hash]))
{
duplicateFiles.Add(hashes[hash]);
}
duplicateFiles.Add(file);
}
else
{
hashes[hash] = file;
}
}
}
}
}
return duplicateFiles;
}
/*
代码说明
FindDuplicateFilesGrouped 方法:
首先遍历传入的文件路径数组,将每个文件的信息(Id、FileName、FileSize)封装到 FileInfoEntity 对象中,并添加到 fileInfos 列表。
接着按文件大小对 fileInfos 进行分组,得到 sizeGroups。
针对每个大小组,计算组内每个文件的哈希值,把具有相同哈希值的文件存到 hashGroups 字典里。
最后,将 hashGroups 中包含多个文件的组添加到 duplicateFileGroups 列表,该列表即为最终按组返回的重复文件结果。
通过这种方式,就能方便地找出所有重复文件,并将它们按组分类返回。
*/
// 入参是文件路径数组,按组返回重复文件
public static List<List<FileInfoEntity>> FindDuplicateFilesGrouped(string[] filePaths)
{
var fileInfos = new List<FileInfoEntity>();
foreach (var filePath in filePaths)
{
var fileInfo = new FileInfo(filePath);
fileInfos.Add(new FileInfoEntity
{
Id = Guid.NewGuid(),
FileName = filePath,
FileSize = fileInfo.Length
});
}
var sizeGroups = fileInfos.GroupBy(f => f.FileSize);
var duplicateFileGroups = new List<List<FileInfoEntity>>();
foreach (var sizeGroup in sizeGroups)
{
if (sizeGroup.Count() > 1)
{
var hashGroups = new Dictionary<string, List<FileInfoEntity>>();
foreach (var file in sizeGroup)
{
using (FileStream stream = File.OpenRead(file.FileName))
{
string hash = CalculateHash(stream);
if (!hashGroups.ContainsKey(hash))
{
hashGroups[hash] = new List<FileInfoEntity>();
}
hashGroups[hash].Add(file);
}
}
foreach (var hashGroup in hashGroups.Values)
{
if (hashGroup.Count > 1)
{
duplicateFileGroups.Add(hashGroup);
}
}
}
}
return duplicateFileGroups;
}
}
}
//
// Program.cs
// See https://aka.ms/new-console-template for more information
using ConsoleApp1_CompareFiles;
Console.WriteLine("Hello, World!");
string[] filePaths = {
"C:\\Users\\Aa\\Desktop\\新建文件夹\\1.txt",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\2.txt",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\3.txt",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\4.xlsx",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\5.xlsx",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\6.docx",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\7.docx",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\8.jpeg",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\9.jpeg",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\捕获 - 副本.PNG",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\捕获.PNG",
"C:\\Users\\Aa\\Desktop\\新建文件夹\\微信图片_20250221165428.png",
};
string folderPath = @"C:\Users\Aa\Desktop\新建文件夹";
string[] allFiles = FileComparisonTool.GetAllFilesInFolder(folderPath);
var duplicateFileGroups = FileComparisonTool.FindDuplicateFilesGrouped(allFiles);
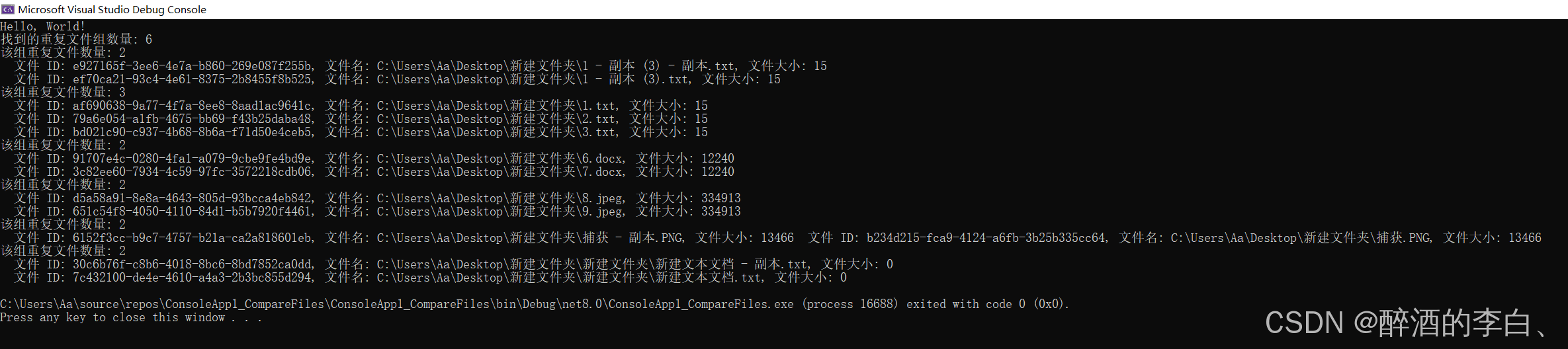
Console.WriteLine($"找到的重复文件组数量: {duplicateFileGroups.Count}");
foreach (var group in duplicateFileGroups)
{
Console.WriteLine($"该组重复文件数量: {group.Count}");
foreach (var file in group)
{
Console.WriteLine($" 文件 ID: {file.Id}, 文件名: {file.FileName}, 文件大小: {file.FileSize}");
}
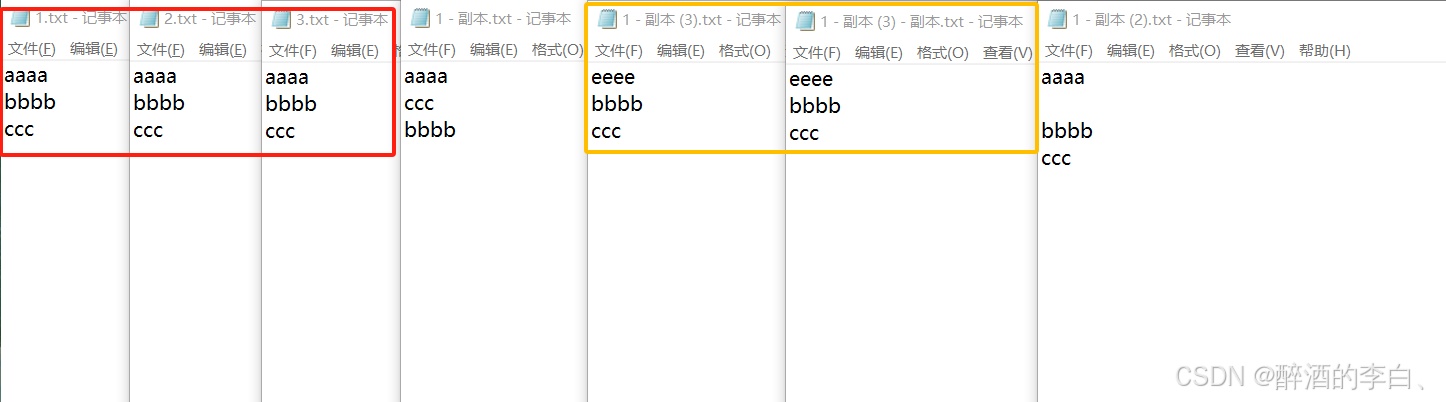
}实现效果:
测试文件.txt文本的举例子。可以看到黄框和红框内的都属于相同文件。红框和黄框内的虽然字节数是一样的,相同大小会group by到一组。但是hash值肯定是不同的。
到此这篇关于.NET下根据文件的哈希值筛选重复文件的文章就介绍到这了,更多相关.net哈希值筛选重复文件内容请搜索站长网以前的文章或继续浏览下面的相关文章希望大家以后多多支持站长网!