问题背景介绍
在大型互联网或企业级应用中,数据库往往成为系统性能的瓶颈。随着数据量和并发量的增长,单一的 SQL 查询可能出现响应迟缓、锁等待、全表扫描等性能问题。为保证系统的稳定性和用户体验,需要对 SQL 查询做深入的调优。常见的调优手段包括索引优化、查询重写、分库分表、缓存方案等。本文将从多种方案入手,对比分析各自优缺点,并结合真实生产环境案例展示调优效果。
多种解决方案对比
方案 A:索引优化
- 原理:为频繁筛选或排序的列建立合适的索引,避免全表扫描。
- 实现:使用 B-Tree、哈希索引或覆盖索引。
示例:为订单表的 user_id 和 created_at 建联合索引:
ALTER TABLE orders ADD INDEX idx_user_created (user_id, created_at DESC);
使用 EXPLAIN 查看执行计划:
EXPLAIN SELECT * FROM orders WHERE user_id = 1234 ORDER BY created_at DESC LIMIT 10;
方案 B:查询重写与分页优化
- 原理:通过拆分复杂 SQL,避免大范围排序与联表;优化分页查询。
- 实现:利用覆盖索引分页、二次过滤或游标。
示例:传统高页码分页会严重影响性能:
SELECT * FROM orders WHERE user_id = 1234 ORDER BY created_at DESC LIMIT 100000, 20;
重写为“基于最后读取位置的分页”:
-- 前一页最后一行的 created_at 值 SET @last_time = '2024-07-01 12:34:56'; SELECT * FROM orders WHERE user_id = 1234 AND created_at < @last_time ORDER BY created_at DESC LIMIT 20;
方案 C:分区表 & 分库分表
- 原理:通过按时间或用户 ID 手动/自动划分表或数据库,减少单表或单库数据量。
- 实现:MySQL 原生分区、Proxy 层分片、ShardingSphere 等。
示例:按月份进行分区:
ALTER TABLE orders
PARTITION BY RANGE (TO_DAYS(created_at)) (
PARTITION p202407 VALUES LESS THAN (TO_DAYS('2024-08-01')),
PARTITION p202408 VALUES LESS THAN (TO_DAYS('2024-09-01'))
);
方案 D:缓存层(Redis)
- 原理:将热点查询结果缓存在内存中,减少数据库压力。
- 实现:使用 Redis 哈希、Sorted Set 或自定义缓存策略。
示例:通过 Spring Cache 简单集成:
@Service
public class OrderService {
@Cacheable(value = "orderList", key = "#userId")
public List<Order> getRecentOrders(long userId) {
return orderMapper.findByUserOrderByCreatedAt(userId, 20);
}
}
各方案优缺点分析
| 方案 | 优点 | 缺点 |
|---|---|---|
| 索引优化 | 最基础、低成本;即插即用;显著减少全表扫描 | 建索引占用空间;写入性能略有下降;对复杂查询提升有限 |
| 查询重写 | 针对性强;可解决分页等特定问题 | 代码层复杂度上升;需分析不同场景重写策略 |
| 分区/分表 | 支撑超大规模数据;单表/单库规模可控 | 设计和运维复杂;跨分区/跨库查询难;可能导致跨库事务问题 |
| 缓存层 | 减少数据库压力;提升响应速度 | 缓存一致性、热点失效、二级缓存上下文复杂 |
选型建议与适用场景
数据量中等(百万级)且查询模式稳定:优先考虑 方案 A:索引优化 与 方案 B:查询重写。低成本、风险小。
业务增长迅速、表数据量突破千万甚至亿级:结合 方案 C:分区表/分库分表。大型电商、日志系统等。
热点数据重复访问高:在以上方案基础上引入 方案 D:缓存层。防止缓存雪崩采用双层缓存或预热策略。
混合场景:可按业务模块拆分策略(OLTP 与 OLAP 分离),或采用 HTAP 数据库(如 TiDB)兼顾多种需求。
实际应用效果验证
场景:电商订单列表查询
- 典型 SQL:按照用户查询、按下单时间倒序分页。
- 初始数据:orders 表记录量 5000 万,按页码分页时 5000 页后响应时间超 2s。
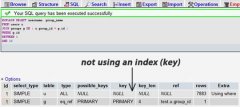
优化前 EXPLAIN:
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | rows | Extra | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | orders | ALL | NULL | NULL | 50000000| Using filesort | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
- 方案 A 索引优化:新增
(user_id, created_at)联合索引后,响应时间降至 200ms。 - 方案 B 分页重写:基于
created_at游标分页,5000 页查询 95% 都在 50ms 内完成。 - 方案 C 分库分表:按用户哈希分 8 库后,最慢页响应 < 100ms。
- 方案 D Redis 缓存:热点前 100 页结果均在 5ms 内返回。
综合来看,方案 A + 方案 B 是快速见效的低成本首选;方案 C + 方案 D 可结合应对超高并发与 PB 级数据量。
到此这篇关于MySQL中SQL查询常见调优方案对比与实践的文章就介绍到这了,更多相关SQL查询调优内容请搜索站长网以前的文章或继续浏览下面的相关文章希望大家以后多多支持站长网!
+1
赞
赏
 分享
分享